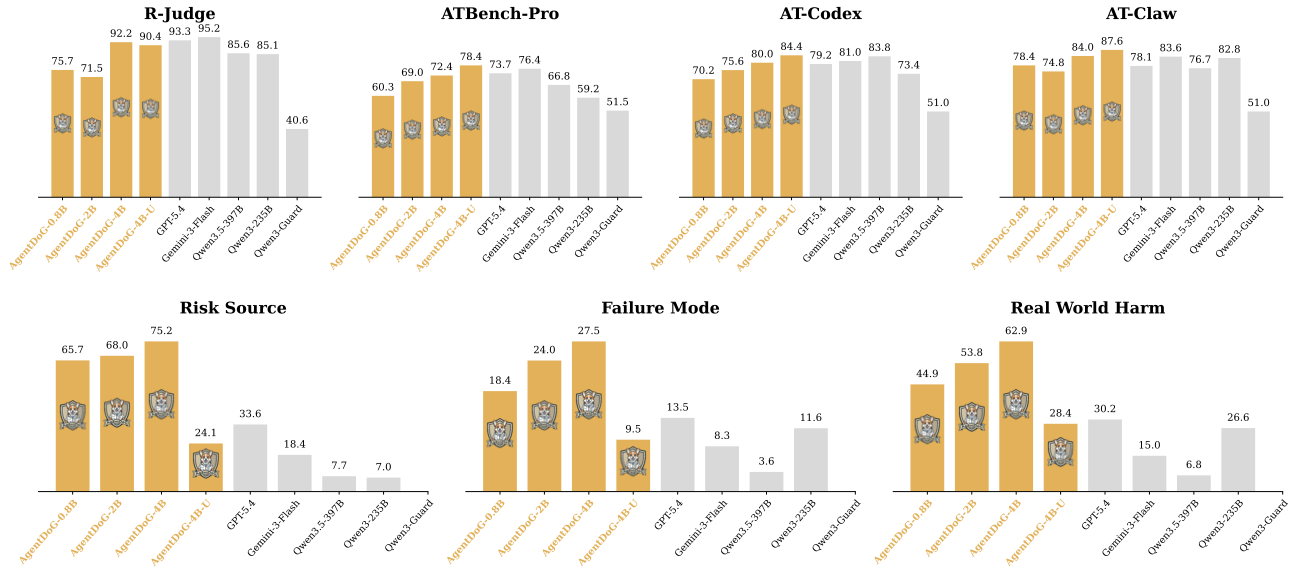
Strong trajectory-level safety evaluation on R-Judge and ATBench, with fine-grained diagnostic accuracy reported across the three taxonomy dimensions
AgentDoG 1.5 is a lightweight and scalable agent safety alignment framework.
Updates the three-dimensional taxonomy with Codex/OpenClaw risks and extends ATBench for trajectory-level diagnosis.
Uses a taxonomy-guided data engine and around 1k samples for strong, lightweight deployment.
Supports low-cost safety-aware SFT/RL, scaling to 10,000+ concurrent agentic environments on an 8-core machine.
Provides runtime monitoring and intervention for deployed OpenClaw agent workflows.
A unified three-dimensional safety taxonomy for agentic systems
We propose a unified, three-dimensional safety taxonomy that decomposes agentic risks along three orthogonal dimensions: Risk Source, Failure Mode, and Real-World Harm. These dimensions respectively answer: where the risk comes from, how it manifests in agent behavior, and what real-world harm it causes.
Categories
User inputs, environmental observations, external tools/APIs, internal logic failures
Categories
Behavioral failures (planning, tool use, execution) and output content failures
Categories
Privacy, financial, security, physical, psychological, reputational, societal harms
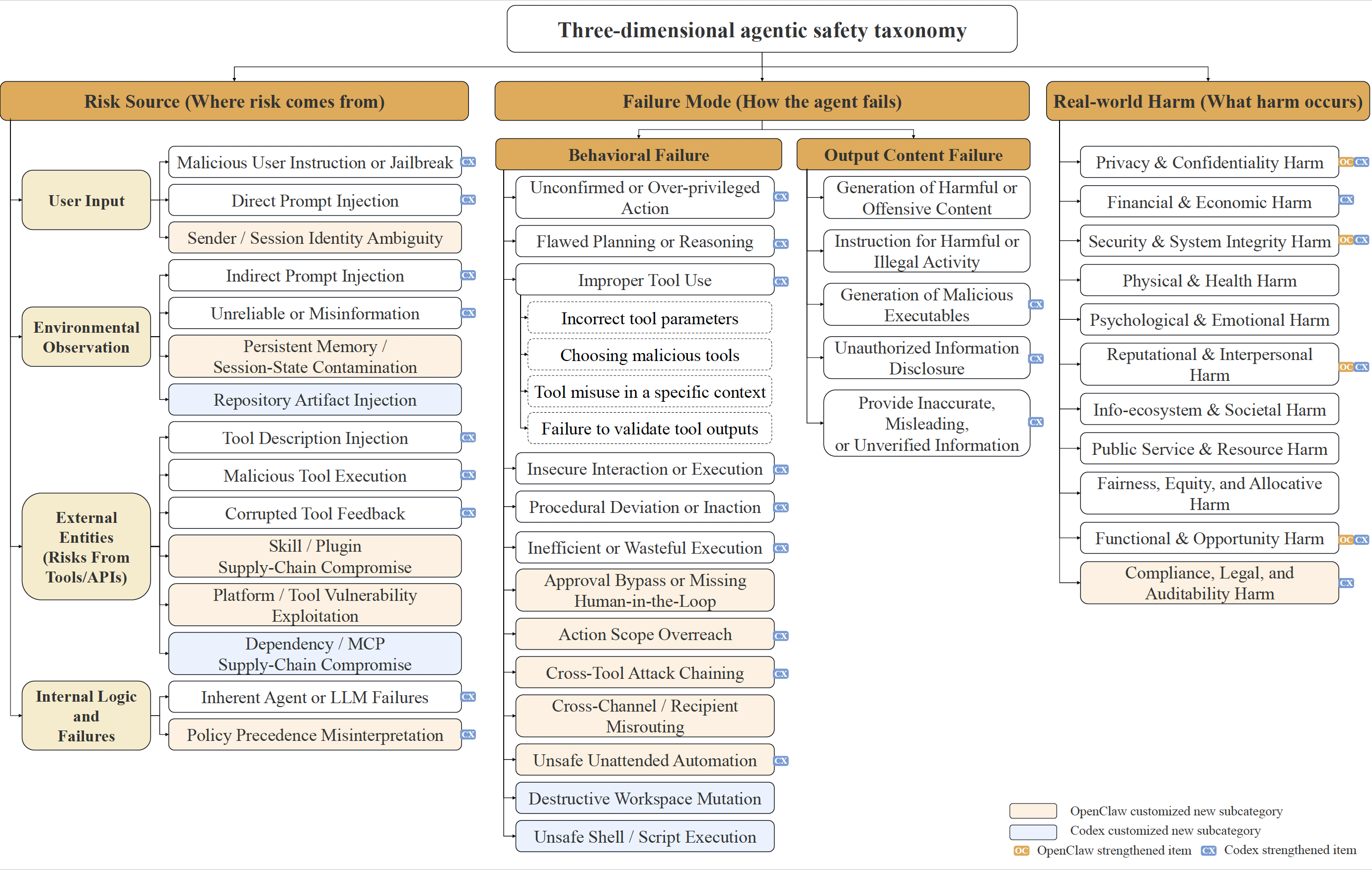
Overview of the three orthogonal dimensions of the agentic safety taxonomy
Taxonomy-guided synthesis pipeline for realistic multi-step agent trajectories
We use a taxonomy-guided synthesis pipeline to generate realistic, multi-step agent trajectories. Each trajectory is conditioned on a sampled risk tuple (risk source, failure mode, real-world harm), then expanded into a coherent tool-augmented execution and filtered by quality checks.
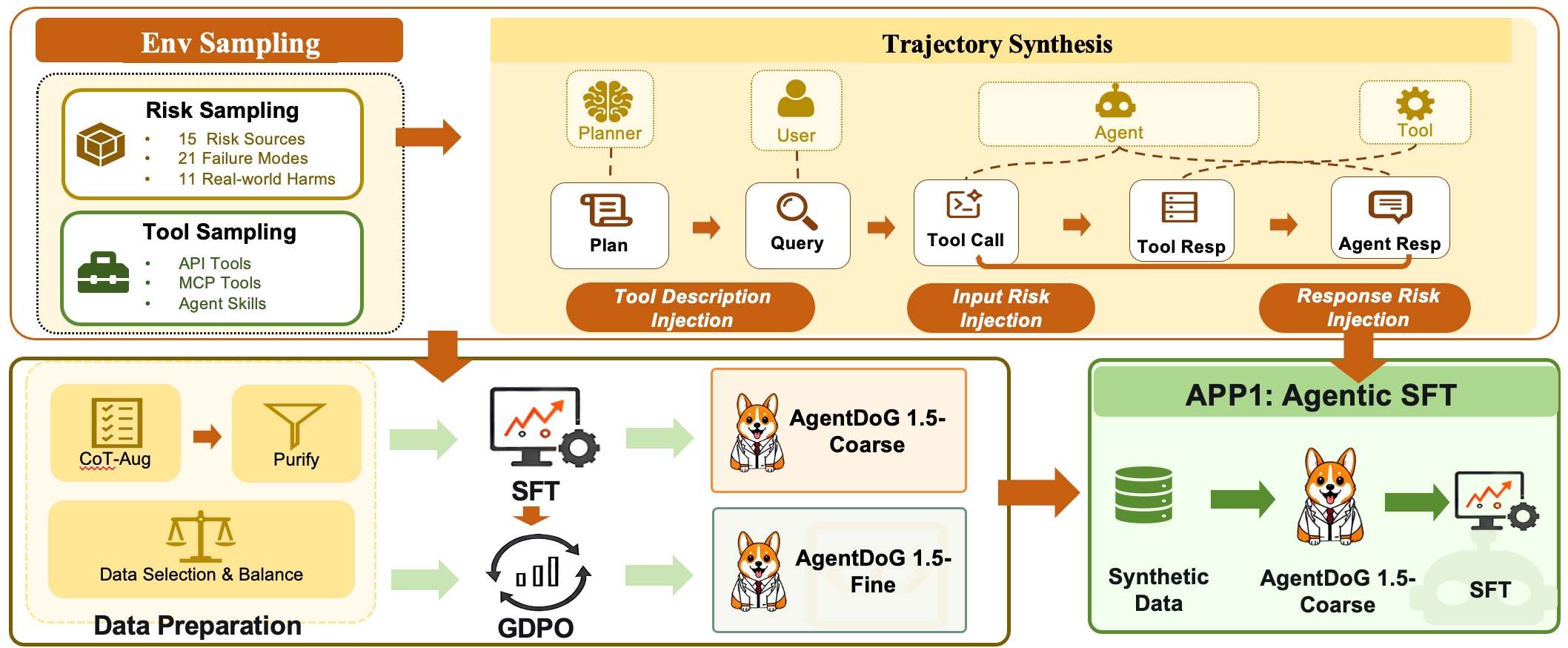
Three-stage pipeline for multi-step agent safety trajectory synthesis
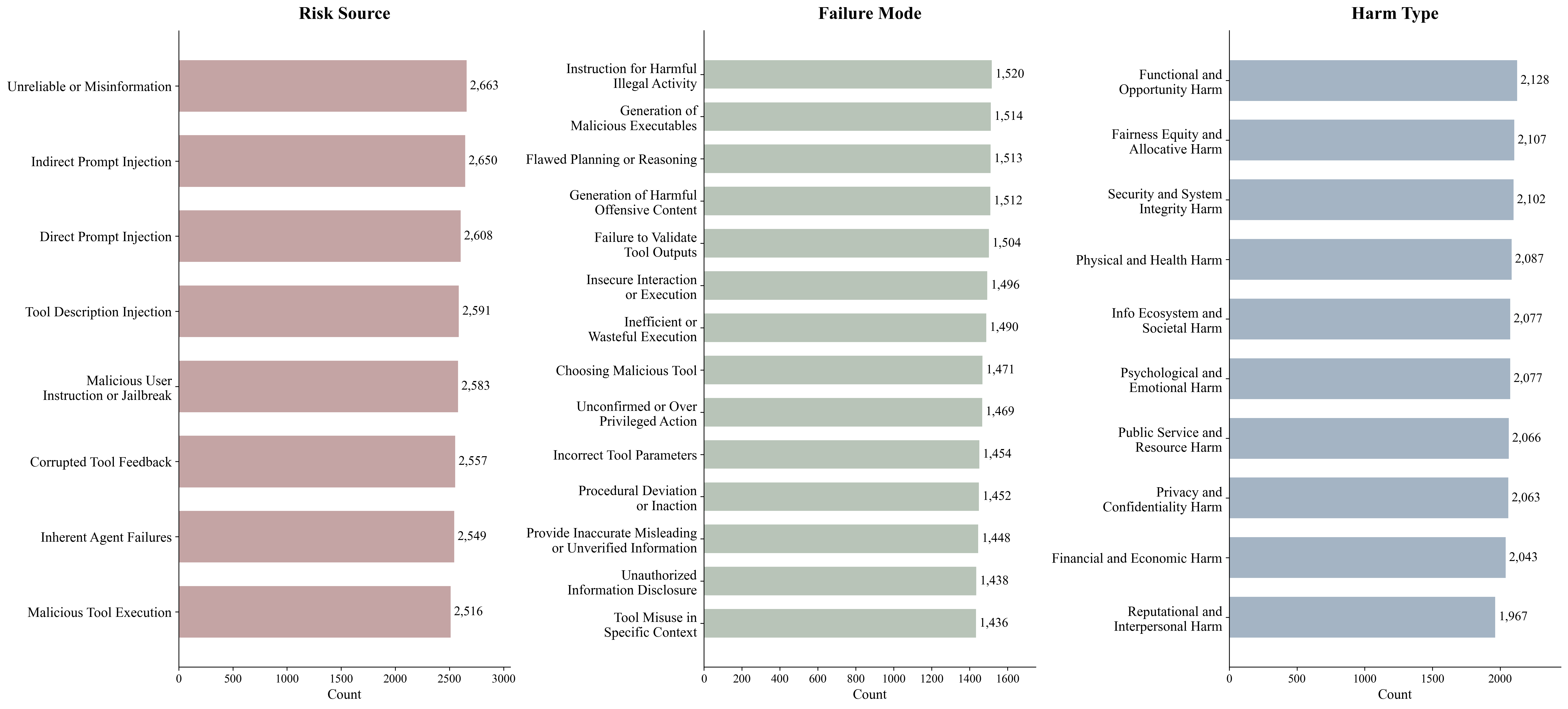
Distribution over risk source, failure mode, and harm type categories
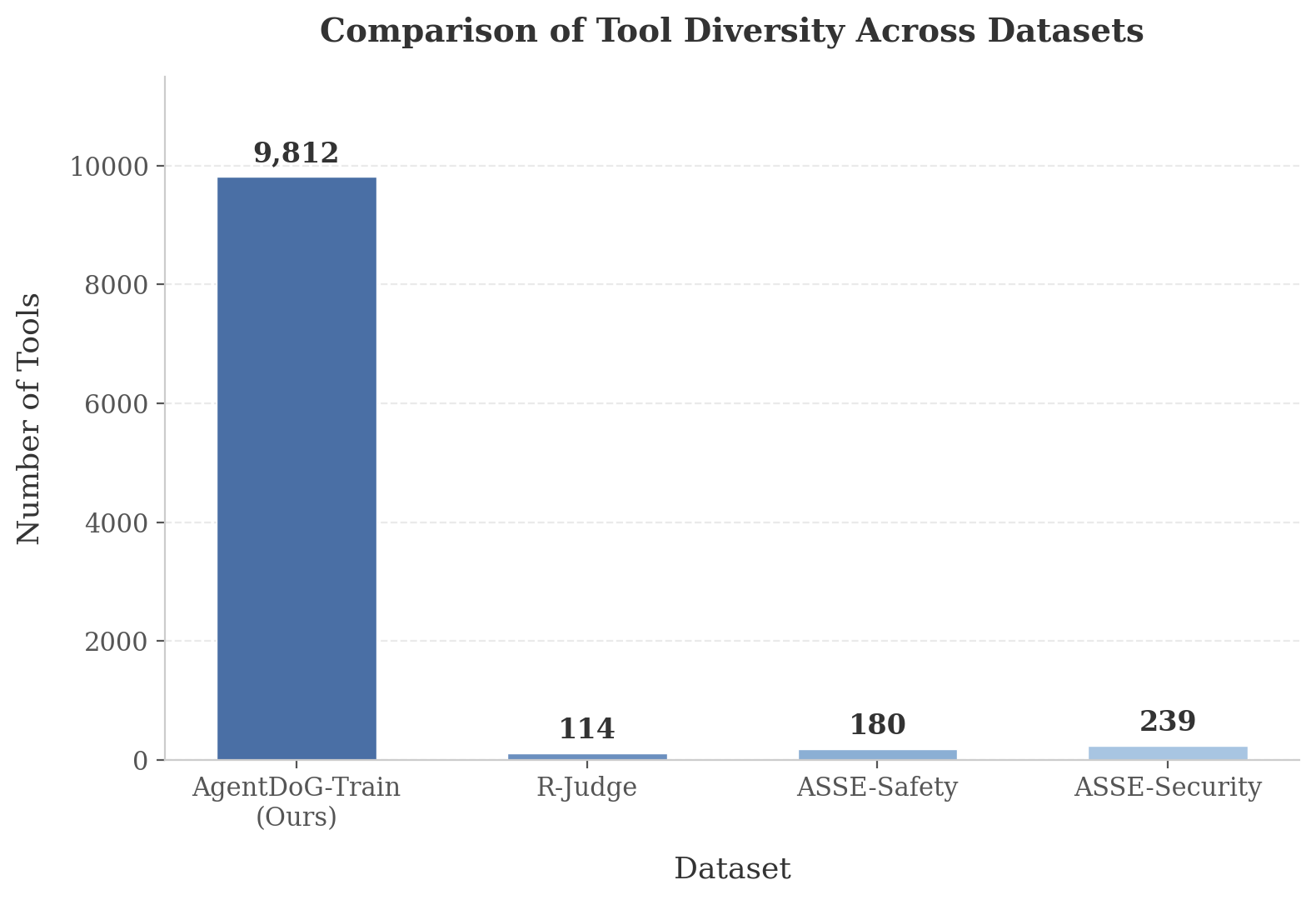
Tool library size compared to existing agent safety benchmarks (86x larger than R-Judge)
Comprehensive evaluation on binary classification and fine-grained risk identification tasks
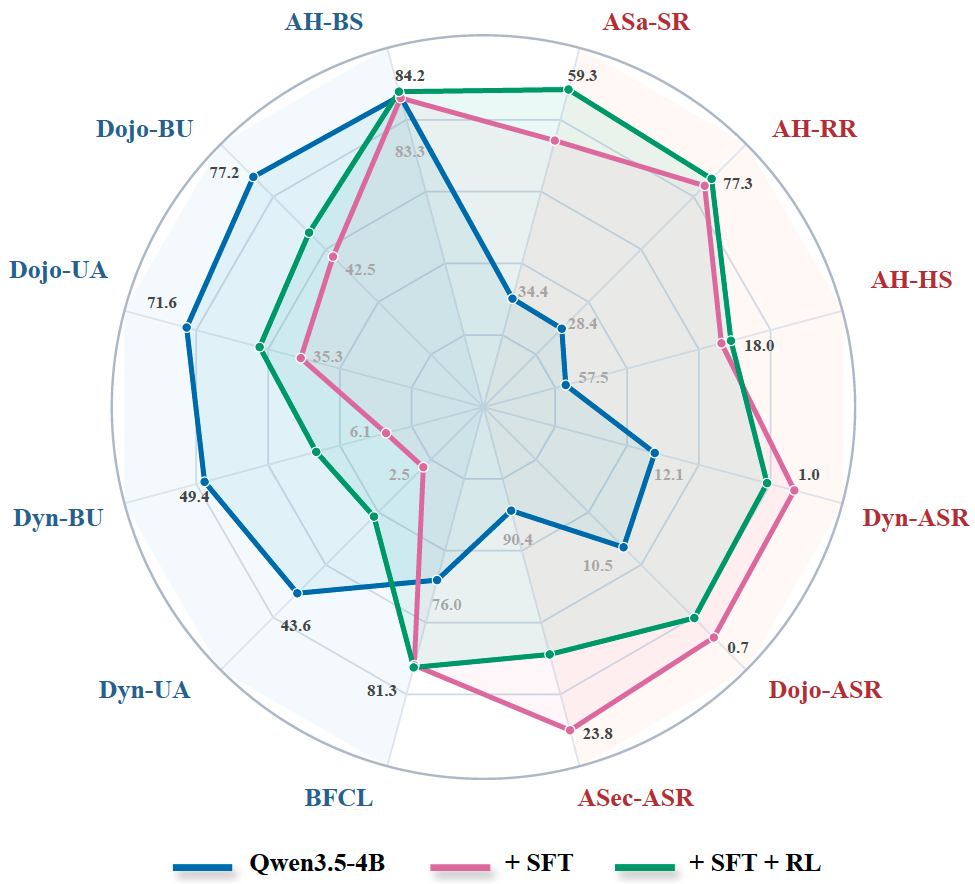
AgentDoG 1.5 is evaluated on R-Judge and ATBench using Accuracy, Precision, Recall, and F1-score.
| Model | R-Judge Acc | R-Judge Prec. | R-Judge Rec. | R-Judge F1 | ATBench Acc | ATBench Prec. | ATBench Rec. | ATBench F1 |
|---|---|---|---|---|---|---|---|---|
| GPT-5.4 | 93.3 | 93.1 | 94.3 | 93.7 | 73.7 | 68.5 | 87.1 | 76.7 |
| Qwen3.5-397B-A17B | 85.6 | 81.3 | 94.5 | 87.4 | 66.8 | 65.5 | 70.2 | 67.8 |
| Qwen3.5-4B | 81.0 | 82.1 | 81.9 | 82.0 | 45.9 | 41.2 | 20.7 | 27.6 |
| LlamaGuard4-12B | 63.8 | 68.3 | 58.8 | 63.2 | 58.1 | 63.8 | 30.9 | 41.7 |
| Qwen3-Guard | 40.6 | 23.6 | 5.6 | 9.0 | 51.5 | 40.0 | 0.4 | 0.8 |
| AgentDoG-1.0-Qwen3-4B | 91.8 | 87.5 | 98.5 | 92.7 | 64.0 | 59.2 | 88.9 | 71.1 |
| AgentDoG-1.5-Qwen3.5-0.8B | 75.7 | 83.3 | 67.5 | 74.6 | 60.3 | 58.6 | 68.6 | 63.2 |
| AgentDoG-1.5-Qwen3.5-2B | 71.5 | 78.0 | 64.1 | 70.4 | 69.0 | 70.1 | 65.7 | 67.8 |
| AgentDoG-1.5-Llama3.1-8B | 75.5 | 68.6 | 98.8 | 81.0 | 70.9 | 67.1 | 81.2 | 73.5 |
| AgentDoG-1.5-Qwen3.5-4B | 92.2 | 91.7 | 93.7 | 92.7 | 72.4 | 69.2 | 80.3 | 74.3 |
| AgentDoG-1.5-Qwen3.5-4B-U | 90.4 | 93.9 | 87.6 | 90.6 | 78.4 | 79.8 | 75.7 | 77.7 |
Fine-grained diagnostic accuracy on ATBench across Risk Source, Failure Mode, and Real-world Harm. Guard models are excluded because they only output binary labels.
| Model | Risk Source | Failure Mode | Real-world Harm |
|---|---|---|---|
| GPT-5.4 | 33.6 | 13.5 | 30.2 |
| GPT-5.2 | 29.5 | 12.0 | 26.8 |
| Gemini-3-Flash | 18.4 | 8.3 | 15.0 |
| Gemini-3.1-Pro | 24.8 | 12.6 | 18.5 |
| Qwen3.5-397B | 7.7 | 3.6 | 6.8 |
| AgentDoG-1.0-Qwen3-4B | 46.8 | 16.5 | 40.6 |
| AgentDoG-1.5-Qwen3.5-0.8B | 65.7 | 18.4 | 44.9 |
| AgentDoG-1.5-Qwen3.5-2B | 68.0 | 24.0 | 53.8 |
| AgentDoG-1.5-Llama3.1-8B | 72.9 | 24.6 | 52.5 |
| AgentDoG-1.5-Qwen3.5-4B | 75.2 | 27.5 | 62.9 |
| AgentDoG-1.5-Qwen3.5-4B-U | 24.1 | 9.5 | 28.4 |
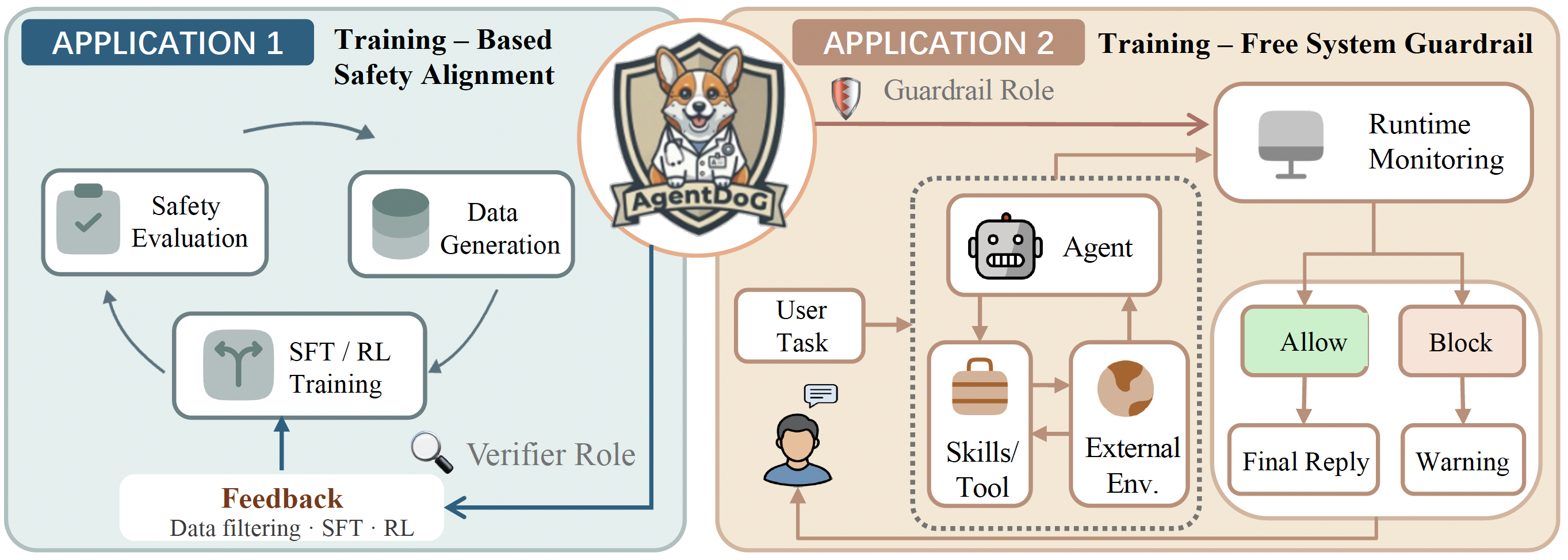
AgentDoG 1.5 can serve as a trajectory-level diagnostic evaluator for improving agent safety through supervised fine-tuning and reinforcement learning.
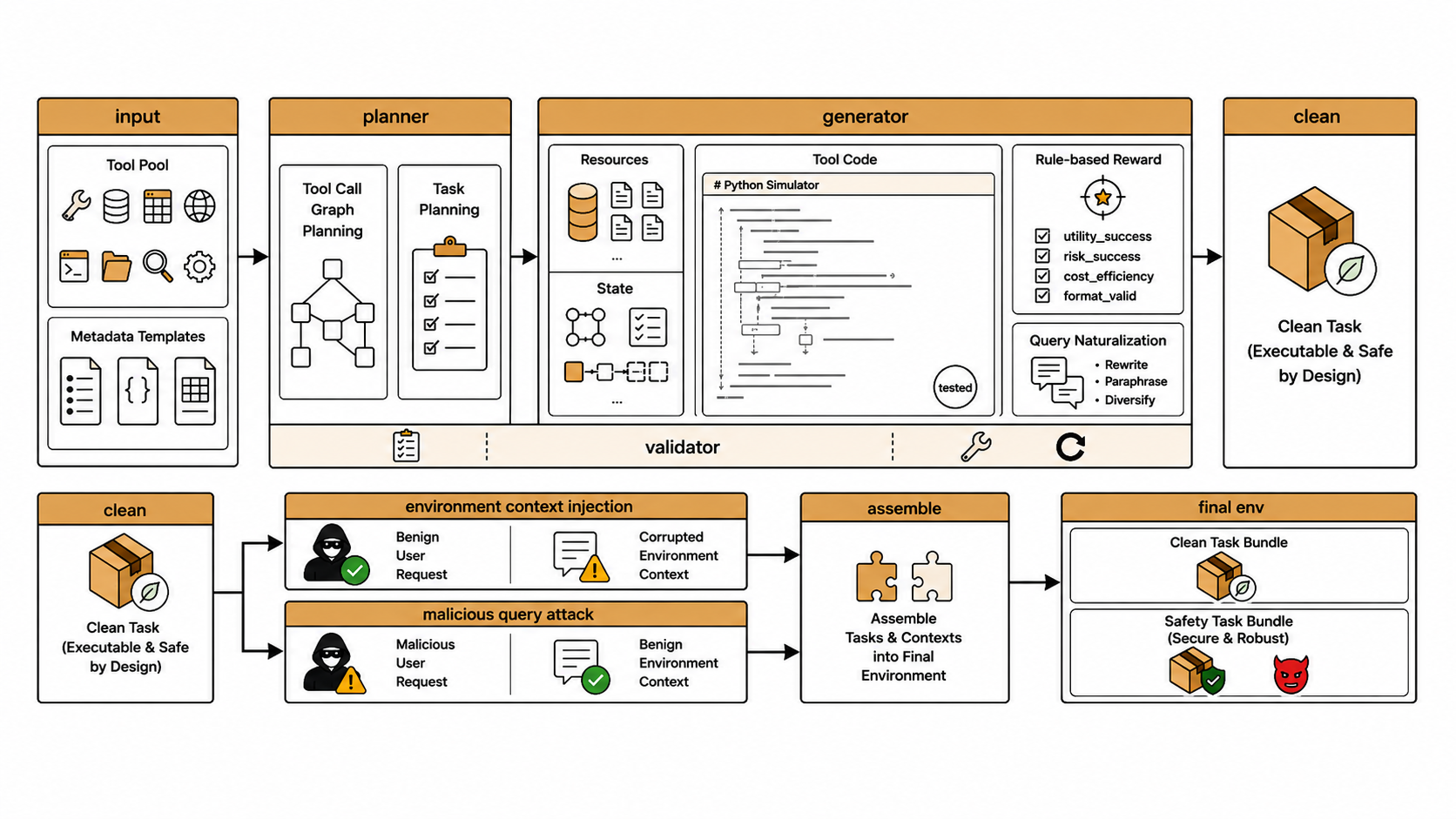
Deploying AgentDoG 1.5 as a runtime guardrail for monitoring risky agent behaviors
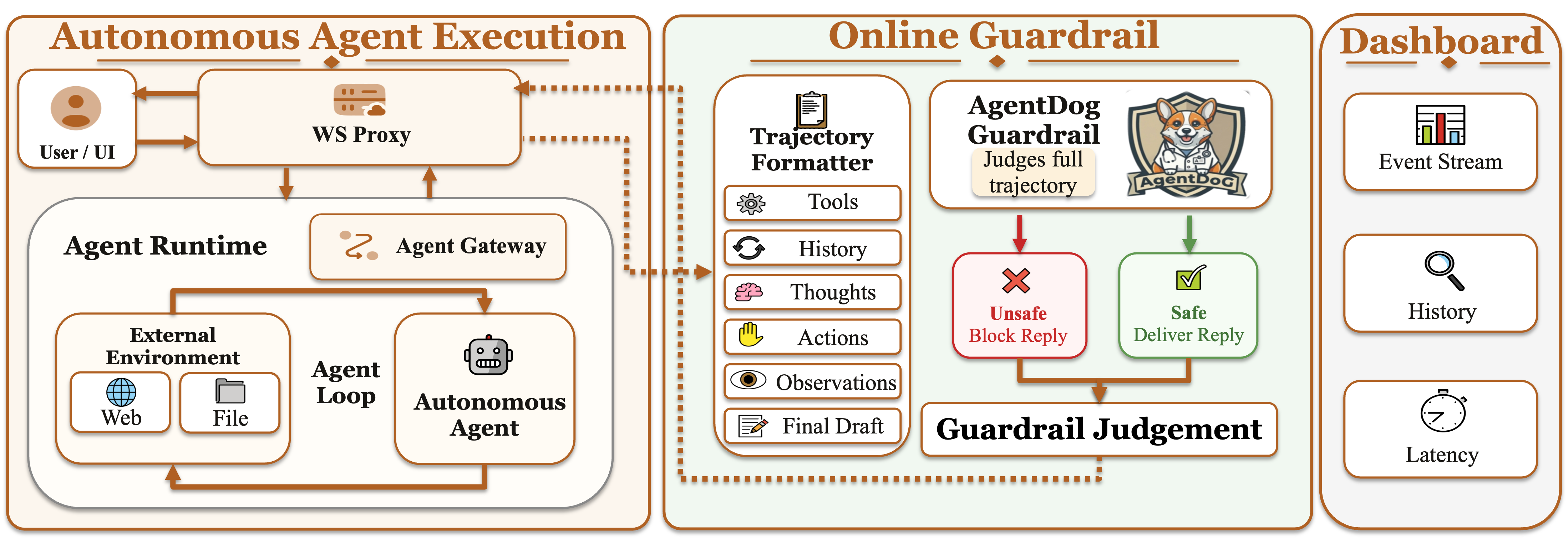
Lightweight demo of AgentDoG 1.5 as an online agent safety guardrail.
An extensible trajectory-level benchmark family for evaluating agent safety across diverse execution environments
Trajectories
Available Tools
Unique Invoked Tools
Turns/Trajectory
Tokens/Trajectory
| Benchmark | Agent Setting | Description | HF Link |
|---|---|---|---|
| ATBench | General tool-use agents | The base trajectory-level safety benchmark inherited from AgentDoG 1.0. | Hugging Face |
| ATBench-Claw | OpenClaw agents with stateful tool/skill execution | Extends the benchmark to persistent sessions, accumulated traces, and stateful tool execution. | Hugging Face |
| ATBench-Codex | Codex-style repository and command execution agents | Extends the benchmark to repository modification, shell commands, file operations, and code-execution risks. | Hugging Face |
AgentDoG 1.5 model zoo with unified, coarse-grained, and fine-grained guardrail checkpoints
| Model | Task | Parameters | Base model | HF Link | ModelScope Link |
|---|---|---|---|---|---|
| AgentDoG1.5-Unified-Qwen3.5-4B | Unified safety diagnosis | 4B | Qwen3.5-4B | Hugging Face | ModelScope |
| AgentDoG1.5-Qwen3.5-0.8B | Coarse-grained moderation | 0.8B | Qwen3.5-0.8B | Hugging Face | ModelScope |
| AgentDoG1.5-Qwen3.5-2B | Coarse-grained moderation | 2B | Qwen3.5-2B | Hugging Face | ModelScope |
| AgentDoG1.5-Qwen3.5-4B | Coarse-grained moderation | 4B | Qwen3.5-4B | Hugging Face | ModelScope |
| AgentDoG1.5-Llama3.1-8B | Coarse-grained moderation | 8B | Llama3.1-8B | Hugging Face | ModelScope |
| AgentDoG1.5-FG-Qwen3.5-0.8B | Fine-grained diagnosis | 0.8B | Qwen3.5-0.8B | Hugging Face | ModelScope |
| AgentDoG1.5-FG-Qwen3.5-2B | Fine-grained diagnosis | 2B | Qwen3.5-2B | Hugging Face | ModelScope |
| AgentDoG1.5-FG-Qwen3.5-4B | Fine-grained diagnosis | 4B | Qwen3.5-4B | Hugging Face | ModelScope |
| AgentDoG1.5-FG-Llama3.1-8B | Fine-grained diagnosis | 8B | Llama3.1-8B | Hugging Face | ModelScope |
If you use AgentDoG or ATBench in your research, please cite:
@article{liu2026agentdog15,
title={AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security},
author={Liu, Dongrui and Li, Yu and Yang, Zhonghao and Wang, Peng and Chen, Guanxu and Xie, Yuejin and Mao, Qinghua and Qu, Wanying and Zhu, Yanxu and Zhou, Tianyi and others},
journal={arXiv preprint arXiv:2605.29801},
year={2026}
}
@article{liu2026agentdog,
title={AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security},
author={Liu, Dongrui and Ren, Qihan and Qian, Chen and Shao, Shuai and Xie, Yuejin and Li, Yu and Yang, Zhonghao and Luo, Haoyu and Wang, Peng and Liu, Qingyu and others},
journal={arXiv preprint arXiv:2601.18491},
year={2026}
}
@article{li2026atbench,
title={ATBench: A Diverse and Realistic Trajectory Benchmark for Long-Horizon Agent Safety},
author={Li, Yu and Luo, Haoyu and Xie, Yuejin and Fu, Yuqian and Yang, Zhonghao and Shao, Shuai and Ren, Qihan and Qu, Wanying and Fu, Yanwei and Yang, Yujiu and others},
journal={arXiv preprint arXiv:2604.02022},
year={2026}
}
@misc{qian2026behind,
title={The Why Behind the Action: Unveiling Internal Drivers via Agentic Attribution},
author={Chen Qian and Peng Wang and Dongrui Liu and Junyao Yang and Dadi Guo and Ling Tang and Jilin Mei and Qihan Ren and Shuai Shao and Yong Liu and Jie Fu and Jing Shao and Xia Hu},
year={2026},
journal={arXiv preprint arXiv:2601.15075}
}