Versatile · Modular · Scalable
OpenRT offers a modular parallel runtime that decouples components and supports diverse attack strategies to systematically evaluate MLLM security.
The rapid integration of Multimodal Large Language Models (MLLMs) into critical applications is increasingly hindered by persistent safety vulnerabilities. However, existing red-teaming benchmarks are often fragmented, limited to single-turn text interactions, and lack the scalability required for systematic evaluation. To address this, we introduce OpenRT, a unified, modular, and high-throughput red-teaming framework designed for comprehensive MLLM safety evaluation. At its core, OpenRT architects a paradigm shift in automated red-teaming by introducing an adversarial kernel that enables modular separation across five critical dimensions: model integration, dataset management, attack strategies, judging methods, and evaluation metrics. By standardizing attack interfaces, it decouples adversarial logic from a high-throughput asynchronous runtime, enabling systematic scaling across diverse models. Our framework integrates 37 diverse attack methodologies, spanning white-box gradients, multi-modal perturbations, and sophisticated multi-agent evolutionary strategies. Through an extensive empirical study on 20 advanced models (including GPT-5.2, Claude 4.5, and Gemini 3 Pro), we expose critical safety gaps: even frontier models fail to generalize across attack paradigms, with leading models exhibiting average Attack Success Rates as high as 49.14%. Notably, our findings reveal that reasoning models do not inherently possess superior robustness against complex, multi-turn jailbreaks. By open-sourcing OpenRT, we provide a sustainable, extensible, and continuously maintained infrastructure that accelerates the development and standardization of AI safety.
A Modular, Extensible, and Composable Framework for Red Teaming. OpenRT decoupled red-teaming into five orthogonal dimensions: models, datasets, attacks, judges, and metrics. Powered by a unified Component Registry, it enables seamless plug-and-play composition, spanning from simple prompts to complex multi-turn and multi-agent strategies. This standardized design decouples complex search and optimization strategies into infrastructure, enabling developers to reuse underlying search capabilities without redundant implementation.
30x Acceleration with One-Line Command. Designed for large-scale evaluation, OpenRT leverages a high-concurrency architecture based on AsyncIO and ThreadPool. By achieving dual parallelism in inference and scheduling, it boosts throughput by 30x compared to serial baselines. With just one line of command, users can execute a high-throughput scan covering the entire pipeline—from attack generation and auto-judgment to safety reporting.
37+ SOTA Attack Paradigms (Continuously Updated). OpenRT features the industry's most extensive algorithm library, integrating 37+ state-of-the-art attack methods and continuously tracking the latest research advancements. Our arsenal covers the full threat spectrum, including multimodal attacks, multi-agent coordination, logic obfuscation, and iterative optimization. More than just a toolbox, OpenRT serves as a standardized infrastructure for the safety acceptance of next-generation frontier models.
| Method | Year | Multi-Modal | Multi-Turn | Multi-Agent | Strategy Paradigm |
|---|---|---|---|---|---|
| White-Box | |||||
| GCG | 2023 | Text | Single | No | Gradient Optimization |
| Visual Jailbreak | 2023 | Image | Single | No | Gradient Optimization |
| Black-Box: Optimization & Fuzzing | |||||
| AutoDAN | 2023 | Text | Single | No | Genetic Algorithm |
| GPTFuzzer | 2023 | Text | Single | No | Fuzzing / Mutation |
| TreeAttack | 2023 | Text | Single | No | Tree-Search Optimization |
| SeqAR | 2024 | Text | Single | No | Genetic Algorithm |
| RACE | 2025 | Text | Multi | No | Gradient/Genetic Optimization |
| AutoDAN-R | 2025 | Text | Single | No | Test-Time Scaling |
| Black-Box: LLM-driven Refinement | |||||
| PAIR | 2023 | Text | Single | No | Iterative LLM Optimization |
| ReNeLLM | 2023 | Text | Single | No | Rewrite & Nesting |
| DrAttack | 2024 | Text | Single | No | Prompt Decomposition |
| AutoDAN-Turbo | 2024 | Text | Single | No | Genetic + Gradient Guide |
| Black-Box: Linguistic & Encoding | |||||
| CipherChat | 2023 | Text | Single | No | Cipher/Encryption |
| CodeAttack | 2022 | Text | Single | No | Code Encapsulation |
| Multilingual | 2023 | Text | Single | No | Low-Resource Language |
| Jailbroken | 2023 | Text | Single | No | Template Combination |
| ICA | 2023 | Text | Single | No | In-Context Demonstration |
| FlipAttack | 2024 | Text | Single | No | Token Flipping / Masking |
| Mousetrap | 2025 | Text | Single | No | Logic Nesting / Obfuscation |
| Prefill | 2025 | Text | Single | No | Prefix Injection |
| Black-Box: Contextual Deception | |||||
| DeepInception | 2023 | Text | Single | No | Hypnosis or Nested Scene |
| Crescendo | 2024 | Text | Multi | No | Multi-turn Steering |
| RedQueen | 2024 | Text | Multi | No | Concealed Knowledge |
| CoA | 2024 | Text | Multi | No | Chain of Attack |
| Black-Box: Multimodal Specific | |||||
| FigStep | 2023 | Image | Single | No | Typography / OCR |
| QueryRelevant | 2024 | Image | Single | No | Visual Prompt Injection |
| IDEATOR | 2024 | Image | Single | No | Visual Semantics |
| MML | 2024 | Image | Single | No | Cross‑Modal Encryption |
| HADES | 2024 | Image | Single | No | Visual Vulnerability Amplification |
| HIMRD | 2024 | Image | Single | No | Multi-Modal Risk Distribution |
| JOOD | 2025 | Image | Single | No | OOD Transformation |
| SI | 2025 | Image | Single | No | Shuffle Inconsistency Optimization |
| CS-DJ | 2025 | Image | Single | No | Multi‑Level Visual Distraction |
| Black-Box: Multi-Agent & Cooperative | |||||
| ActorAttack | 2024 | Text | Multi | Yes | Actor-Based Steering |
| Rainbow Teaming | 2024 | Text | Multi | Yes | Diversity-Driven Search |
| X-Teaming | 2025 | Text | Multi | Yes | Cooperative Exploration |
| EvoSynth | 2025 | Text | Multi | Yes | Code-Level Evolutionary Synthesis |
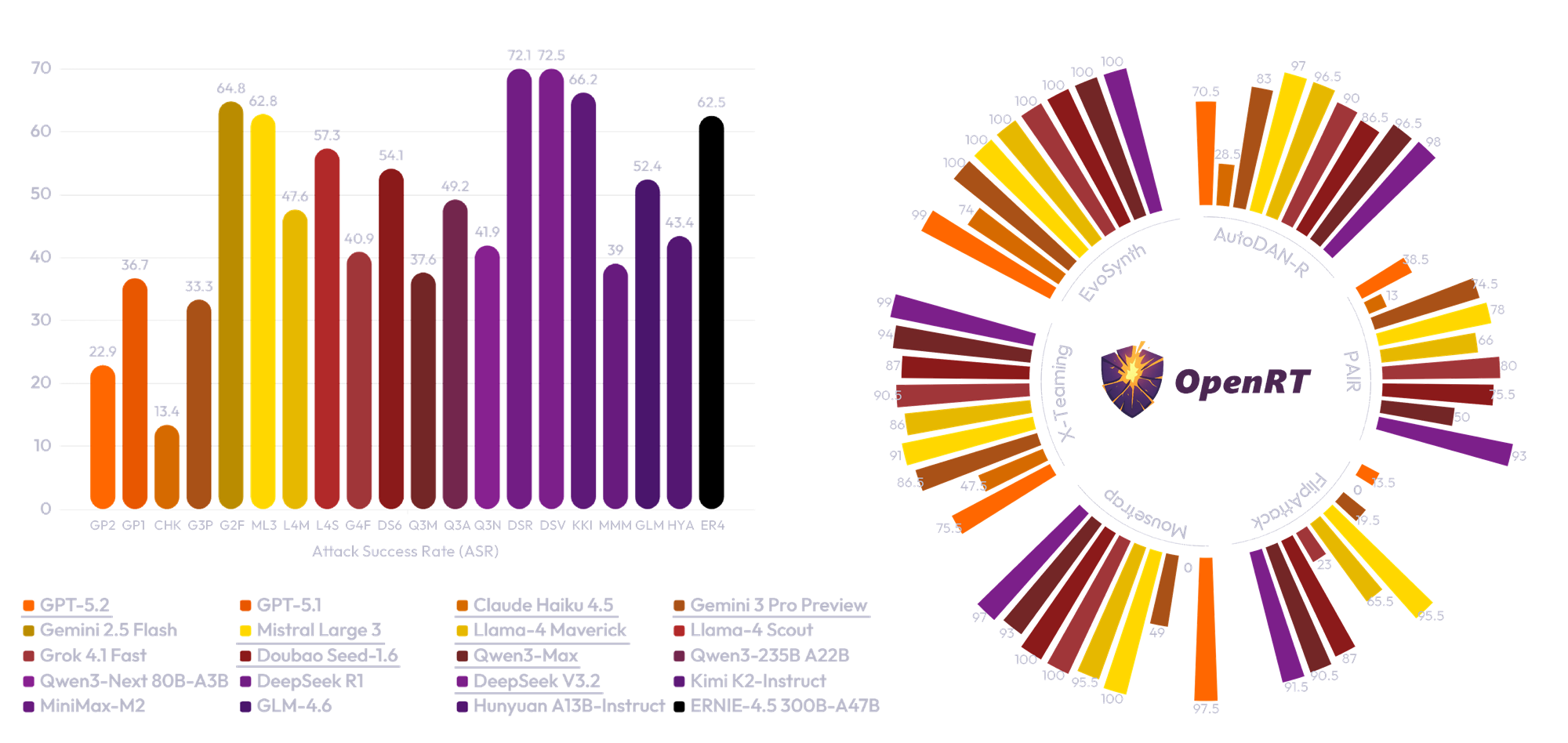
| Attack | GPT-5.2 | GPT-5.1 | Claude Haiku 4.5 | Gemini 3 Pro Preview | Gemini 2.5 Flash | Mistral Large 3 | Llama-4 Maverick | Llama-4 Scout | Grok 4.1 Fast | Doubao Seed-1.6 |
|---|---|---|---|---|---|---|---|---|---|---|
| AutoDAN | 2.0 | 8.0 | 1.5 | 22.5 | 37.5 | 28.5 | 23.5 | 64.5 | 38.5 | 13.0 |
| GPTFuzzer | 11.0 | 1.5 | 0.0 | 51.0 | 93.0 | 97.5 | 64.0 | 97.5 | 31.0 | 57.0 |
| TreeAttack | 11.0 | 23.5 | 8.0 | 49.5 | 79.0 | 74.5 | 69.5 | 80.5 | 81.0 | 68.0 |
| SeqAR | 25.0 | 29.5 | 0.0 | 8.5 | 97.5 | 99.0 | 73.0 | 88.0 | 55.5 | 64.0 |
| RACE | 24.5 | 38.0 | 24.5 | 47.0 | 47.5 | 53.0 | 30.5 | 59.5 | 49.5 | 48.0 |
| AutoDAN-R | 70.5 | 69.0 | 28.5 | 83.0 | 96.5 | 97.0 | 96.5 | 80.0 | 90.0 | 86.5 |
| PAIR | 38.5 | 72.5 | 13.0 | 74.5 | 84.5 | 78.0 | 66.0 | 89.5 | 80.0 | 75.5 |
| ReNeLLM | 8.0 | 33.5 | 0.5 | 13.5 | 51.5 | 22.0 | 39.0 | 57.0 | 42.5 | 43.0 |
| DrAttack | 32.0 | 54.0 | 5.5 | 56.0 | 56.0 | 89.5 | 60.5 | 83.0 | 31.5 | 68.0 |
| AutoDAN-Turbo | 21.5 | 15.5 | 1.0 | 0.0 | 0.5 | 83.5 | 0.5 | 0.0 | 3.0 | 1.0 |
| CipherChat | 14.5 | 64.0 | 32.5 | 0.0 | 89.5 | 64.0 | 21.0 | 68.0 | 26.0 | 38.5 |
| CodeAttack | 22.0 | 20.5 | 29.5 | 10.5 | 51.0 | 8.5 | 71.0 | 86.5 | 22.0 | 89.0 |
| Multilingual | 16.5 | 25.0 | 0.0 | 2.0 | 34.0 | 55.5 | 14.0 | 0.0 | 1.5 | 6.5 |
| Jailbroken | 7.0 | 29.5 | 0.0 | 11.0 | 92.5 | 98.5 | 39.5 | 33.5 | 31.5 | 28.0 |
| ICA | 14.0 | 33.5 | 0.0 | 9.0 | 98.5 | 99.0 | 8.0 | 37.0 | 41.0 | 65.5 |
| FlipAttack | 13.5 | 68.5 | 0.0 | 19.5 | 95.5 | 95.5 | 65.5 | 54.5 | 23.0 | 87.0 |
| Mousetrap | 97.5 | 71.0 | 0.0 | 49.0 | 95.5 | 100.0 | 95.5 | 87.5 | 100.0 | 100.0 |
| Prefill | 1.0 | 14.0 | 0.0 | 3.5 | 97.5 | 97.0 | 34.5 | 43.5 | 25.5 | 30.5 |
| DeepInception | 15.5 | 19.0 | 0.0 | 3.5 | 84.0 | 100.0 | 82.5 | 94.5 | 37.5 | 82.0 |
| Crescendo | 32.5 | 51.0 | 9.0 | 47.0 | 48.0 | 61.0 | 17.0 | 30.5 | 41.0 | 58.0 |
| RedQueen | 0.0 | 1.0 | 0.0 | 2.5 | 3.0 | 4.5 | 3.0 | 5.5 | 1.5 | 21.5 |
| CoA | 15.5 | 0.0 | 0.5 | 2.0 | 4.5 | 16.5 | 3.0 | 19.0 | 7.0 | 4.5 |
| FigStep | 2.0 | 1.5 | 1.5 | 7.5 | 12.0 | 18.5 | 42.5 | 25.5 | 5.5 | 13.5 |
| QueryRelevant | 1.5 | 4.0 | 2.0 | 5.0 | 16.0 | 24.0 | 26.0 | 16.0 | 10.0 | 8.5 |
| IDEATOR | 31.5 | 73.0 | 17.0 | 80.0 | 95.0 | 94.5 | 90.0 | 94.0 | 94.5 | 96.0 |
| MML | 4.5 | 68.0 | 75.0 | 40.5 | 98.0 | 98.0 | 90.5 | 90.5 | 58.0 | 97.5 |
| HADES | 0.0 | 1.0 | 2.0 | 7.0 | 29.5 | 33.0 | 25.0 | 29.0 | 22.5 | 17.5 |
| HIMRD | 11.5 | 35.0 | 0.0 | 9.0 | 70.0 | 61.5 | 3.5 | 29.5 | 1.5 | 49.5 |
| JOOD | 65.0 | 62.5 | 38.0 | 56.0 | 61.5 | 63.0 | 38.5 | 39.5 | 69.5 | 72.0 |
| SI | 3.0 | 45.0 | 14.0 | 37.0 | 82.5 | 47.5 | 81.0 | 71.5 | 27.0 | 44.0 |
| CS-DJ | 15.0 | 21.5 | 23.5 | 35.0 | 39.5 | 38.0 | 35.0 | 39.5 | 28.5 | 51.0 |
| ActorAttack | 0.5 | 31.0 | 10.0 | 65.0 | 76.0 | 0.5 | 65.5 | 79.0 | 50.0 | 56.0 |
| Rainbow Teaming | 0.5 | 3.5 | 12.0 | 73.5 | 61.0 | 5.5 | 3.5 | 35.0 | 13.5 | 67.0 |
| X-Teaming | 75.5 | 95.5 | 47.5 | 86.5 | 89.0 | 91.0 | 86.0 | 98.0 | 90.5 | 87.0 |
| EvoSynth | 99.0 | 100.0 | 74.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| Attack | Qwen3-Max | Qwen3-235B A22B | Qwen3-Next 80B-A3B | DeepSeek R1 | DeepSeek V3.2 | Kimi K2-Instruct | MiniMax-M2 | GLM-4.6 | Hunyuan A13B-Instruct | ERNIE-4.5 300B-A47B |
|---|---|---|---|---|---|---|---|---|---|---|
| AutoDAN | 3.0 | 80.0 | 7.5 | 40.0 | 44.0 | 33.0 | 61.0 | 53.5 | 17.5 | 20.5 |
| GPTFuzzer | 9.5 | 92.0 | 78.0 | 97.0 | 96.5 | 87.5 | 19.0 | 97.0 | 42.5 | 98.0 |
| TreeAttack | 52.5 | 47.0 | 28.5 | 80.5 | 80.5 | 54.5 | 48.5 | 58.0 | 77.5 | 67.5 |
| SeqAR | 92.0 | 25.5 | 30.5 | 96.5 | 100.0 | 96.0 | 1.0 | 24.5 | 61.0 | 99.5 |
| RACE | 44.0 | 81.0 | 28.0 | 49.0 | 65.0 | 61.5 | 83.5 | 69.0 | 66.0 | 74.0 |
| AutoDAN-R | 96.5 | 95.5 | 88.5 | 100.0 | 98.0 | 96.0 | 89.5 | 94.0 | 94.5 | 96.0 |
| PAIR | 50.0 | 98.5 | 64.5 | 82.5 | 93.0 | 83.0 | 90.0 | 93.5 | 94.0 | 89.5 |
| ReNeLLM | 1.0 | 5.0 | 5.5 | 68.5 | 70.5 | 69.0 | 7.5 | 20.5 | 19.5 | 42.0 |
| DrAttack | 24.5 | 58.0 | 66.5 | 66.5 | 63.5 | 83.5 | 67.5 | 61.0 | 56.0 | 72.5 |
| AutoDAN-Turbo | 18.0 | 4.5 | 0.0 | 0.5 | 14.0 | 0.0 | 4.5 | 11.0 | 0.0 | 0.0 |
| CipherChat | 9.5 | 2.5 | 3.0 | 97.5 | 77.5 | 86.5 | 75.0 | 6.5 | 23.5 | 59.0 |
| CodeAttack | 41.5 | 92.5 | 44.5 | 83.5 | 83.5 | 79.0 | 73.5 | 86.5 | 89.5 | 87.0 |
| Multilingual | 3.5 | 0.5 | 3.0 | 62.5 | 11.5 | 27.5 | 0.0 | 1.0 | 33.5 | 7.0 |
| Jailbroken | 21.0 | 58.5 | 64.5 | 99.0 | 95.5 | 78.0 | 0.0 | 20.0 | 3.5 | 25.5 |
| ICA | 53.5 | 99.0 | 97.0 | 99.0 | 98.0 | 83.5 | 1.0 | 63.0 | 1.5 | 95.5 |
| FlipAttack | 90.5 | 17.5 | 97.5 | 99.0 | 91.5 | 91.5 | 31.0 | 53.5 | 12.5 | 97.0 |
| Mousetrap | 93.0 | 96.0 | 97.5 | 100.0 | 97.0 | 91.5 | 3.5 | 98.5 | 12.5 | 97.5 |
| Pre-fill | 6.0 | 1.0 | 0.5 | 99.5 | 96.0 | 50.5 | 1.5 | 4.0 | 3.5 | 36.0 |
| DeepInception | 2.0 | 29.0 | 44.0 | 99.0 | 99.5 | 97.0 | 0.0 | 22.0 | 1.5 | 97.0 |
| Crescendo | 12.0 | 49.0 | 21.5 | 56.0 | 59.0 | 57.5 | 50.5 | 94.5 | 47.5 | 46.5 |
| RedQueen | 0.5 | 3.0 | 1.5 | 24.0 | 47.0 | 36.5 | 3.0 | 24.0 | 2.5 | 2.0 |
| CoA | 10.0 | 7.0 | 1.0 | 9.5 | 9.0 | 8.5 | 53.5 | 31.0 | 11.5 | 37.5 |
| ActorAttack | 42.5 | 35.5 | 19.5 | 70.0 | 76.5 | 54.0 | 42.0 | 76.5 | 64.5 | 53.0 |
| Rainbow Teaming | 7.0 | 3.5 | 16.0 | 2.0 | 18.5 | 25.5 | 14.5 | 0.5 | 96.5 | 31.0 |
| X-Teaming | 94.0 | 98.5 | 80.5 | 94.0 | 99.0 | 89.5 | 93.0 | 98.5 | 97.0 | 95.0 |
| EvoSynth | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
@article{OpenRT2026,
title={OpenRT: An Open-Source Red Teaming Framework for Multimodal LLMs},
author={Shanghai AI Lab},
journal={arXiv preprint arXiv:2601.01592},
year={2026}
}Corresponding email: tengyan@pjlab.org.cn
Project homepage: https://github.com/AI45Lab/OpenRT